详解场节点数据的传递机理
概述
无论是瞬态问题、非线性问题,还是多场耦合问题、算子分裂问题,相关的场节点数据的传递过程都是整个程序的核心内容。它对问题的顺利求解起着至关重要的作用。本节将深刻剖析一下场节点数据的传递机理,助力用户设计开发出专用的 NFE 算法文件。
对于一个单独的由有限元语言生成的计算程序,场节点数据的传递路径可以用下图来简单表示。从书写脚本的角点出发,数据传递过程主要依赖于两个关键点,一个是 unod* 文件,用于串联内存和硬盘之间以及不同物理场之间的数据传递;一个是有限元语言语法定义的 coef 语句,用于沟通 NFE 与 PDE/FBC 之间的数据通信。可以说,理解了 unod* 文件和 coef 语句,就理解了有限元语言的精髓。
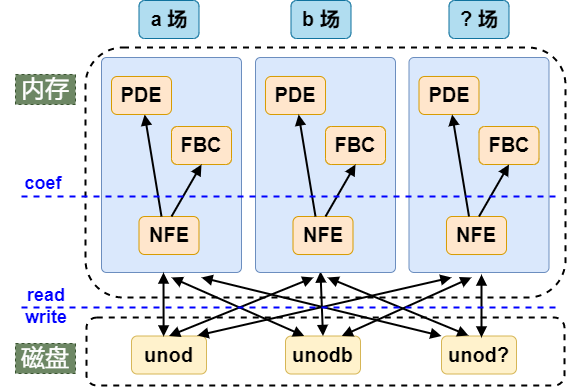
unod* 文件
为了减少内存占用和更便捷地交换不同物理场之间数据,场节点的数据传递经常要用到 unod* 文件(这里用 "*" 字符代表场标识符 a、b、c … )。 它是有限元语言默认使用的临时存储文件,专门用于存储不同物理场的场节点的数据。unod* 这一文件命名方法沿用了 FEPG 系统的命名习惯,以尽量兼容有限元语言的历史版本文件。当 * 场标识符为 a 时,通常将尾部的 * 位置留空,仅以 unod 作为文件名。
有限元语言对 unod* 文件的操作主要来自 GCN 文件中的 #start? 语句(这里用 "?" 字符代表求解器名称,如 sin、nin 和 umf 等)和 NFE 文件的 read 和 write 语句,下面依次给出介绍。
-
GCN 的 #start? 语句
unod* 文件的初始化源于#start? 语句。我们先回顾一下 #start? 的语法规则
#start? 场标识符*
采用 #start? 命令对 * 场进行初始化时,就会自动创建并初始化 unod* 文件,固定地向其写入 4 组数据。
假定场变量以 $u$ 来表示,则写入的数据依次为 $u$、$\dot{u}$ 、$\ddot{u}$ 和 $u$ 在网格节点上的值,即 $u$ 的初始值、 $u$ 对时间一阶导数的初始值、 $u$ 对时间二阶导数的初始值和 $u$ 的初始值。
例如,对于 $u$ 是位移场的情况,unod* 文件在自动创建时,存放的数据依次为:初始位移、初始速度、初始加速度和初始位移。
这些初始数据其实都应该是在前处理时由用户来设定的。 $u$ 的默认值为 0。如果我们在前处理时对某些节点施加了强制约束,则约束值会被保留下来,用于更新 $u$ 在这些节点上的数据。
如果不存在 $\dot{u}$ 或 $\ddot{u}$ 的初始值,则系统会自动用 $u$ 的值来替代它。例如,如果 $\ddot{u}$ 不存在,则写入的数据依次为 $u$、$\dot{u}$ 、$u$ 和 $u$;如果 $\dot{u}$ 和 $\ddot{u}$ 都不存在,则写入的数据依次为 $u$、$u$ 、$u$ 和 $u$。
为什么要这么做呢?这是为了最大程度兼顾 NFE 算法文件的读取需要。后面会看到,有大量的算法需要从 unod* 中读取上一个时间步或迭代步的场变量值。因此 unod* 文件在初始化时必须存储足够多的数据,确保不会出现读取越界的情况。
-
NFE 的 read 和 write 语句
NFE 的 read 和 write 语句是整个有限元语言语法中唯一支持对 unod* 文件的进行直接读写语句。先回顾一下 read 和 write 语句的语法规则
read(s, 文件名) 场变量/向量名,…,场变量/向量名
write(s, 文件名) 场变量/向量名,…,场变量/向量名
顾名思义,read 为读语句,write 为写语句。 使用 s 是因为沿用了 FEPG 系统的命名习惯,代表顺序读写,依次从文件读取或向文件写入场变量或场向量。
读和写操作要求彼此作用的变量的顺序必须保持一致。之前怎么存的,后面就怎么读取。因此读取文件时,用户对存储文件的结构一定要有清楚的认识。
另外,执行 write 语句时,程序会创建新的文件。如果之前已存在该文件,则会将其覆盖掉,从头开始写入。
临时存储文件 unod* 可以说是 read 和 write 语句最常操作的文件。当然,用户完全可以让 read 和 write 语句操作自己命名的其他文件,只不过与 unod* 文件相比,这些文件缺少了前面提到的 #start? 语句所提供的初始化过程。因此,切记要先 write,再 read,以避免出现没有文件可读的尴尬。
-
场变量和场向量
作为 unod* 文件的存储对象,这里有必要补充说明一下场变量和场向量的差别。
场变量和场向量都是表示场节点数据的变量。场变量名由 var 语句声明,场向量名由 vect 语句声明。可以将场变量理解为一维数组,将场向量理解为二维数组。场向量有两个维度,一个维度与场变量的维度完全相同,都是节点总数,另一个维度则是当前物理场的自由度的个数。
可以说,一个场向量是由多个场变量组成的合集。当前的物理场有多少个自由度,一个场向量就等价于多少个场变量。
总的来说,场向量的使用最为常见。#start? 语句对 unod* 文件进行初始化时,写入的也是场向量。而当处理多场耦合等问题时,由于涉及到不同物理场之间的节点数据的交换,此时则必须要使用更加灵活的场变量。大家可以结合相关算例来体会场变量和场向量的具体应用场景。
这样,通过临时存储文件 unod*,结合 read 和 write 语句,利用场变量和场向量,我们就可以轻松实现对场节点的数据进行磁盘读写操作了。
coef 语句
我们首先需要明确这样一个概念:同一个物理场的 PDE/FBC 和 NFE 文件其实是一体的。PDE/FBC 的脚本负责生成单元矩阵,并传递给 NFE 文件。而 NFE 的脚本则继续将 PDE/FBC 提供的单元矩阵组装成为总体矩阵。因此,我们可以将 PDE/FBC 理解成 NFE 的一个子程序。
对于非线性问题和多场耦合问题,PDE/FBC 在生成单元矩阵时可能要用到场节点的数据。不管是当前物理场的场节点的数据,还是其他物理场的场节点的数据,PDE/FBC 究竟是如何获取的呢?这就需要用到 coef 语句了。我们注意到在 NFE 和 PDE/FBC 的语法规范中都存在着 coef 语句,它实际上是扮演了重要的数据通道的角色。下面依次给出详细的介绍。
-
NFE 文件中的 coef 语句
先回顾一下 NFE 文件中的 coef 语句的语法规则。
coef 场变量/向量名,…,场变量/向量名
coef 后面的参数可以是 "场变量名"或者 "场向量名"。如果同时存在场向量和场变量,要求先写场向量名,后写场变量名。
-
PDE/FBC 文件的 coef 语句
下面继续解读 PDE/FBC 文件中的 coef 语句的语法规则。
coef 系数函数名, 系数函数名, … , 系数函数名
coef 后面的系数函数名可以理解为 "场变量/向量名" 的别名,由用户自取,用于声明与场节点数据相关的非线性迭代系数函数或者耦合系数函数。
由于 PDE/FBC 的 coef 行的数据是由 NFE 文件中 coef 行传递过来的。因此,PDE/FBC 和 NFE 文件的 coef 行的系数函数名的先后次序必须保持一致。
我们注意到 NFE 文件中的 coef 语句后面通常是 "场向量名",即按场向量格式传递数据,相当于一次传递多个场变量,而 PDE/FBC 文件中的 coef 语句的后面全是 "场变量名",即按场变量格式一个一个地接收数据。两者之间如何协调呢?为此,这里有以下两点需要特别说明:
- 同样是 coef 行,可能会出现 PDE/FBC 文件中的多个系数函数名对应 NFE 文件中的一个场向量名的情况。这与本场自由度的数量有关。
- 允许主程序多传子程序少收,因此,PDE/FBC 文件中 coef 行系数函数名的数量,也就是它对应的场变量的数量,可以少于 NFE 文件中 coef 行的等价的场变量的数量。反之,少传多收则是被禁止的。
归根结底,PDE/FBC 文件中 coef 行的系数函数名的数量和顺序不是任意的,要与 NFE 的 coef 行的参数相互匹配 。
用一句话总结:能少不能多,名称随意取,位置最重要。
-
范例
考虑单物理场的非线性迭代问题,假定该场有 4 个自由度 u v p q。 它的 NFE 文件的 coef 行有如下定义
coef u1
这里的 u1 为场变量(vect u1)。那么,PDE 文件的 coef 语句可以这样写
coef un vn pn qn
这就声明了该场的系数函数名称分别为 un、vn、pn 和 qn。依据 a 场的场向量所包含的场变量的个数,我们使用了 4 个系数函数来接收 NFE 传递的 1 个场向量的数据。
如果只需要 un 和 vn,不使用 pn 和 qn,上面可以简化一下
coef un vn
这就是上面提到的 "多传少收"。
coef 语句在非线性问题、多场耦合问题和算子分裂问题等领域有着大量的应用,发挥了至关重要的作用。它的学习难度偏高,为了能用对、用好,用户一定要多加练习和体会。
综合算例
推荐读者思考以下几个问题,并仔细研读相关算例,观察其中的 coef、vect/var、read/write 语句,探究一下场节点数据的具体传递路径。
-
瞬态问题的时间步之间的数据传递
- 瞬态热传导算例
-
非线性问题的迭代步之间的数据传递
- 非饱和渗流算例
- 非线性瞬态热传导算例
-
耦合场之间的数据传递
-
弹性静力学算例,重点关注应力场的求解
-
热固耦合算例
-
流体瞬态NS方程算例
-
毫不夸张地说,如果以上算例的每一行语句都理解掌握了,你就可以放开手脚,大胆地去利用有限元语言设计开发自己的专用计算软件了。Good luck !

感谢您的支持,我们会继续努力的!




打开支付宝或微信扫一扫,即可进行扫码打赏哦
